Abstract
Decoder-only transformers have become the standard architecture for large language models (LLMs) due to their strong performance. Recent studies suggest that, in pre-trained LLMs, early, middle, and late layers may serve distinct roles: Early layers focus on understanding the input context, middle layers handle task-specific processing, and late layers convert abstract representations into output tokens. We hypothesize that once representations have been processed by the early and middle layers, the resulting hidden states may encapsulate sufficient information to support the generation of multiple tokens using only the late layers, eliminating the need to repeatedly traverse the early and middle layers. We refer to this inference paradigm as Direct Multi-Token Decoding (DMTD). Unlike speculative decoding, our method introduces no additional parameters, auxiliary routines, or post-generation verification. Despite being trained on a limited dataset, a fine-tuned DMTD Qwen3-4B model has already demonstrated promising results, achieving up to a 2× speedup with only minor performance loss. Moreover, as shown in our scaling analysis, its performance is expected to further improve with larger training datasets.
Main Idea
In our previous work FlexiDepth, we discovered that pre-trained large language models contain redundancy, as many layers can be skipped without affecting performance. However, these layer-skipping patterns are irregular and difficult to provide acceleration in memory-bound scenarios. DMTD repurposes this redundancy into a regular pattern by cyclically reusing the late layers to efficiently generate multiple tokens. Importantly, DMTD introduces no additional parameters, auxiliary routines, or post-generation verification like speculative decoding.
Architecture
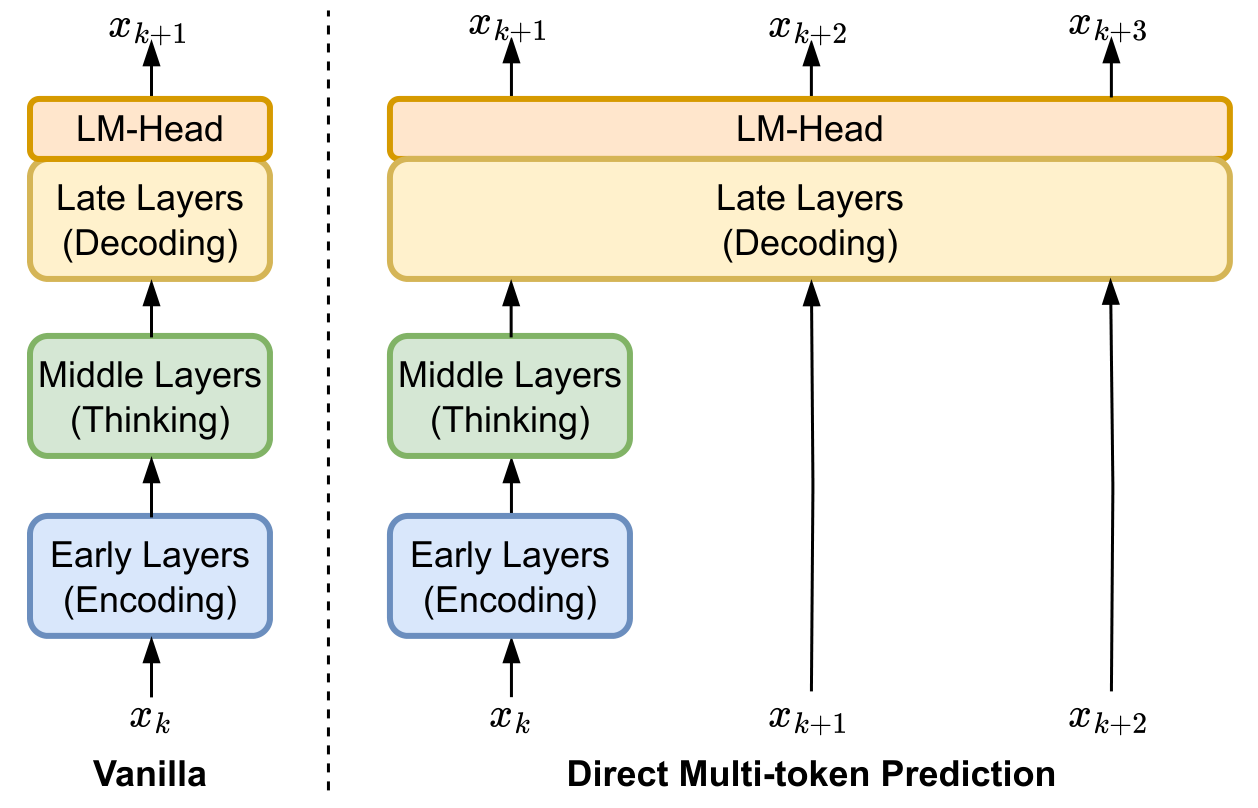
Unlike the vanilla decoder-only transformer that generates tokens one by one through full forward passes, the proposed DMTD operates in fixed multi-token cycles. Figure 1 (right) demonstrates the generation pipeline of DMTD in a single cycle. DMTD performs only one full forward pass at the beginning of the cycle and then reuses the later layers to decode multiple tokens consecutively. This cycle-based setting transforms the irregular computational redundancies observed in pre-trained LLMs into a fixed periodical pattern for efficient decoding.
Scaling with Training Data
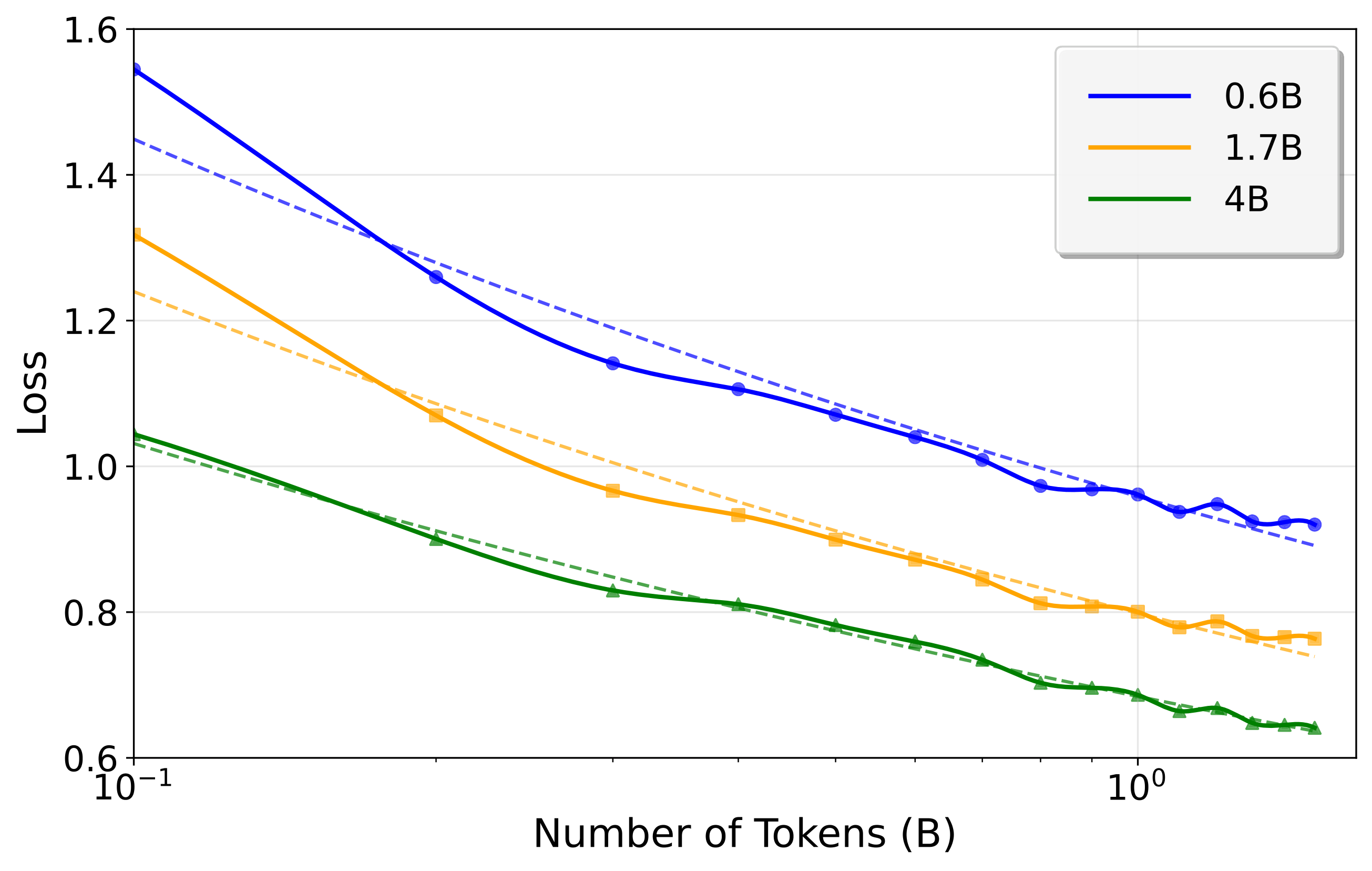
We conducted scaling experiments to understand how DMTD's performance improves with increasing training data across different model sizes (0.5B, 1.5B, 3B, 7B, and 14B parameters). The results reveal a consistent decrease in cross-entropy loss as training data increases for all model sizes, with the trends approximating log-linear relationships. Our current training uses only 1.5B tokens. With large-scale continued pre-training, the performance of our method is expected to improve significantly, potentially enabling each cycle to decode more tokens efficiently.
Results
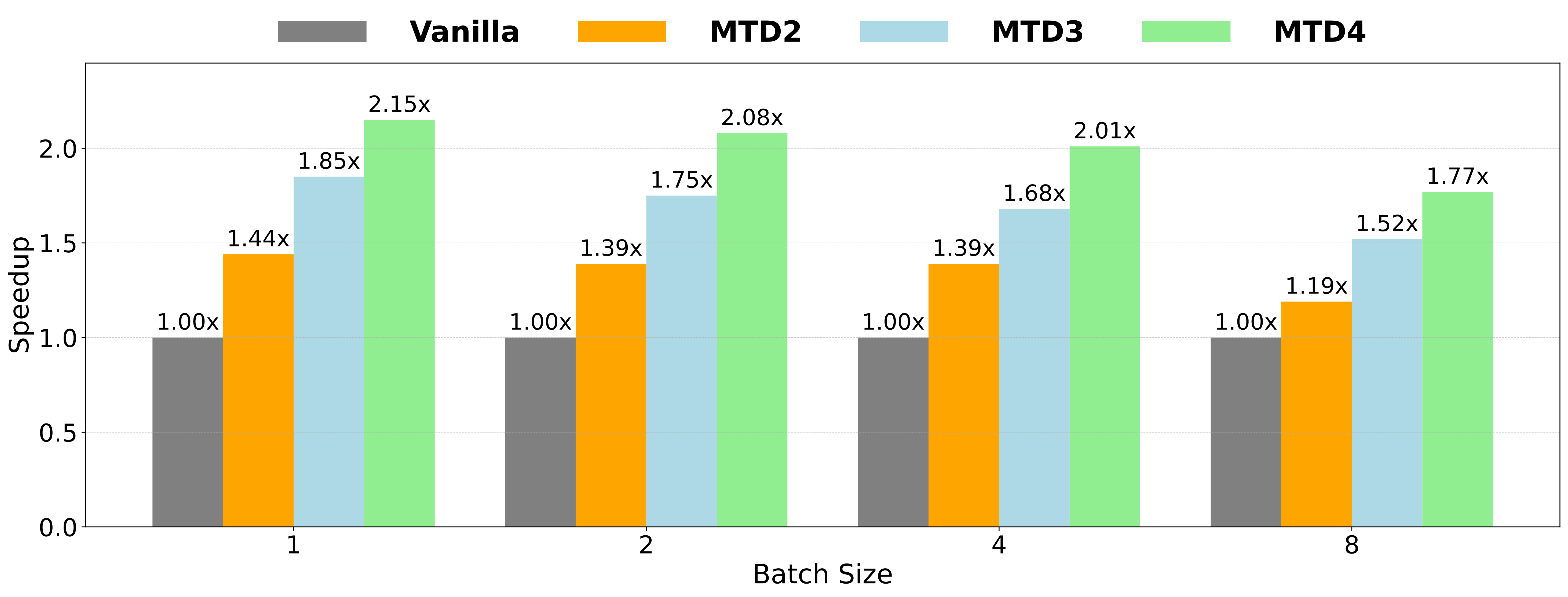
We evaluate our method by reusing the last 8 layers of Qwen3-4B, where MTDx denotes decoding x tokens per cycle (cycle length). As shown in the figure below, our method performs well with cycle lengths up to MTD4.
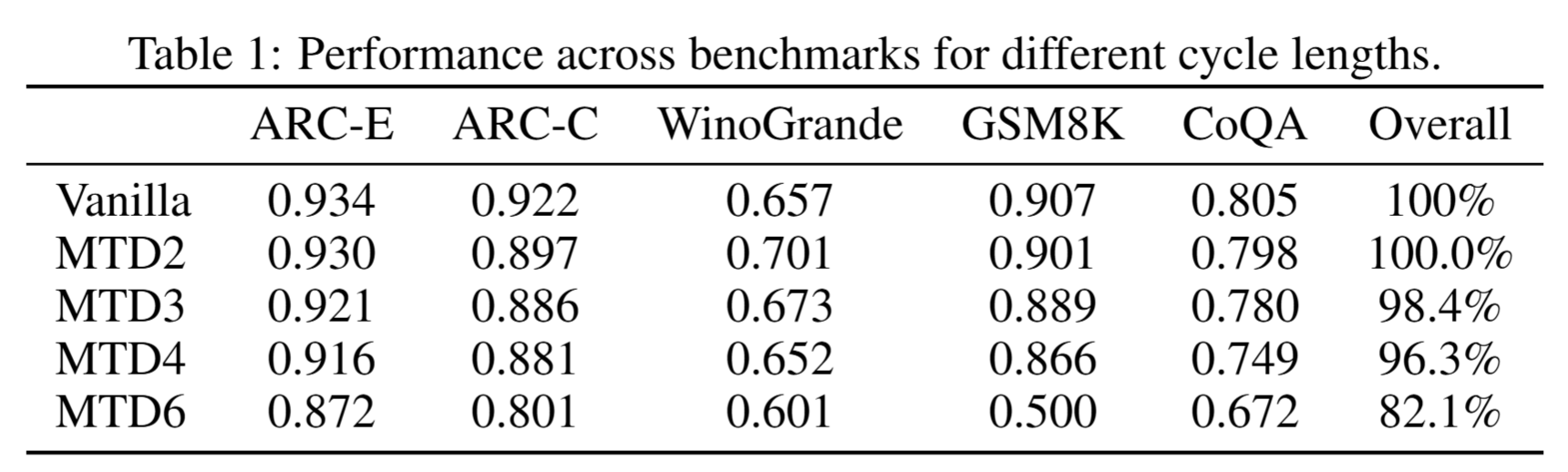
Our method achieves up to 2× speedup when generating 4 tokens per cycle. Importantly, our method does not rely on speculative decoding and is orthogonal to such techniques. It can be compatible with methods like speculative decoding, but for simplicity, we only present the plain results here.