Abstract
Various layer-skipping methods have been proposed to accelerate token generation in large language models (LLMs). However, they have overlooked a fundamental question: How do computational demands vary across the generation of different tokens? In this work, we introduce FlexiDepth, a method that dynamically adjusts the number of Transformer layers used in text generation. By incorporating a plug-in router and adapter, FlexiDepth enables adaptive layer-skipping in LLMs without modifying their original parameters. Introducing FlexiDepth to Llama-3-8B model achieves layer skipping of 8 layers out of 32, and meanwhile maintains the full 100% benchmark performance. Experimental results with FlexiDepth demonstrate that computational demands in LLMs significantly vary based on token type. Specifically, generating repetitive tokens or fixed phrases requires fewer layers, whereas producing tokens involving computation or high uncertainty requires more layers. Interestingly, this adaptive allocation pattern aligns with human intuition. To advance research in this area, we open sourced FlexiDepth and a dataset documenting FlexiDepth's layer allocation patterns for future exploration.
Main Idea
The computational demand varies when generating different tokens. Many transformer layers of pre-trained LLMs can be skipped without compromising performance. Below is an example of FlexiDepth demonstrating that many tokens utilize only a few layers.

For more results about the layer skipping pattern of different tokens, please refer to flexipatterns
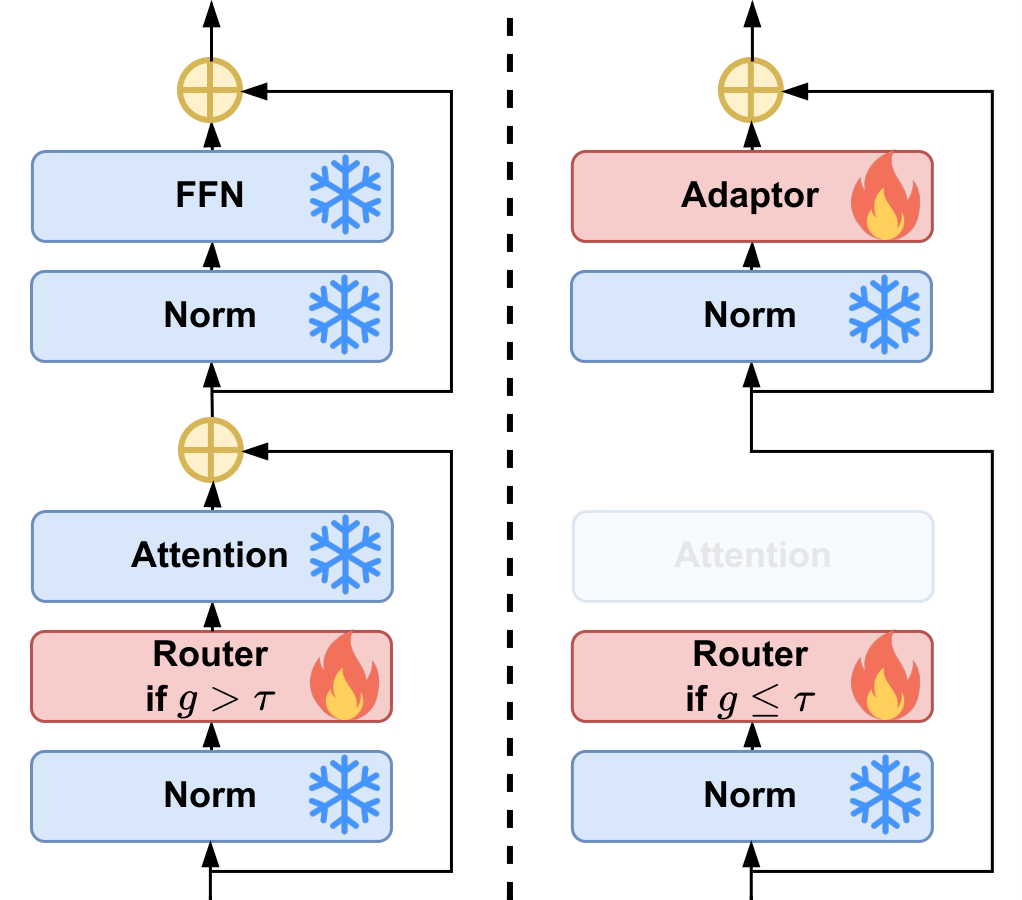
Architecture
Our architecture consists of:
- A router to make layer-skipping decisions.
- An adapter to align skipped hidden states and the processed hidden states.
Results
We experimented on different tasks and observed a "bowl-like" pattern in layer usage, where earlier and later layers are utilized more, while middle layers are used less. We also found differences across tasks: "continue writing" tasks utilize more layers than "summarization" and "copy" tasks, and "product" tasks use more layers than "addition" and "repetition" tasks.
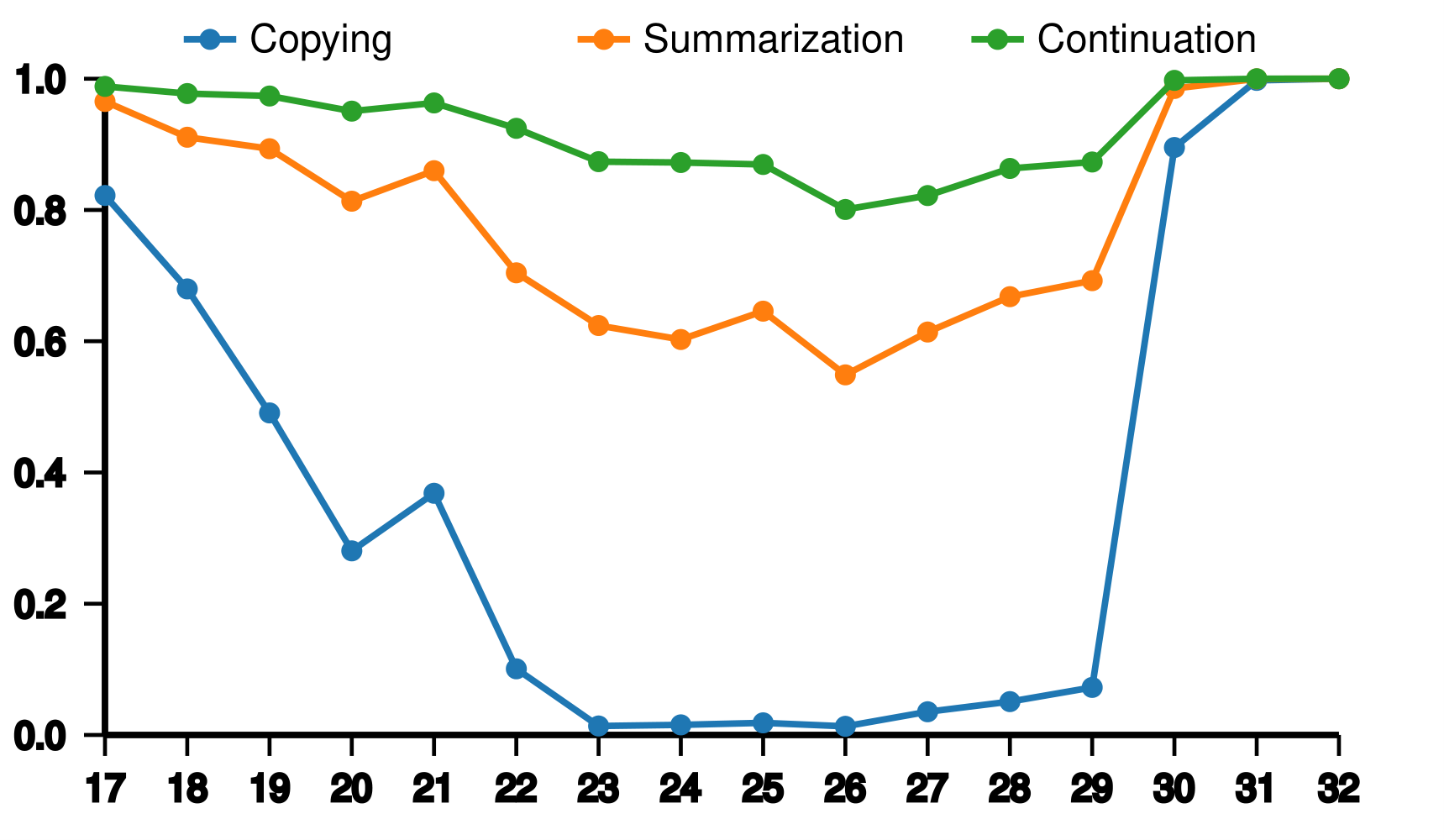
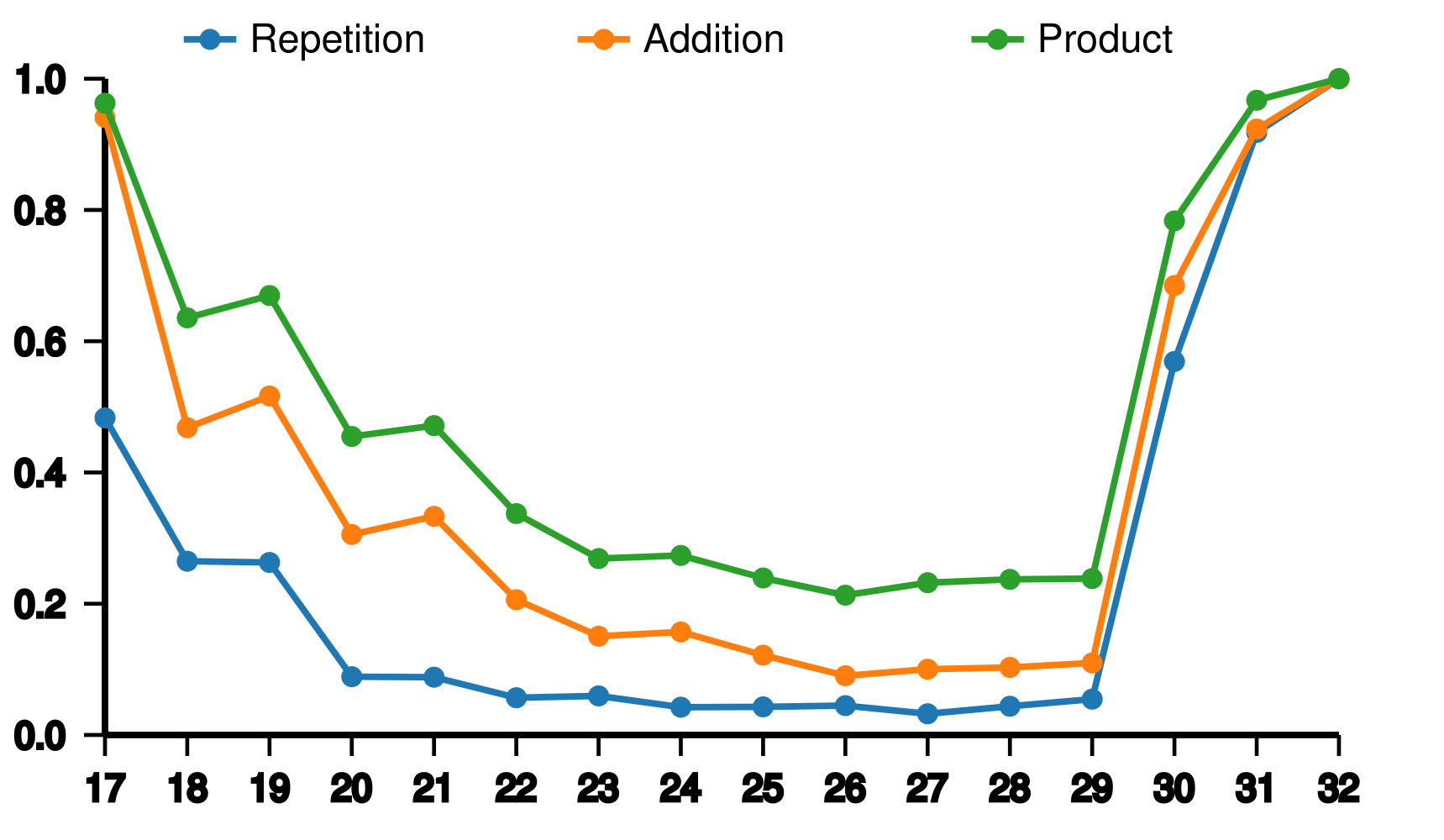
We compared our model with other models to evaluate performance.
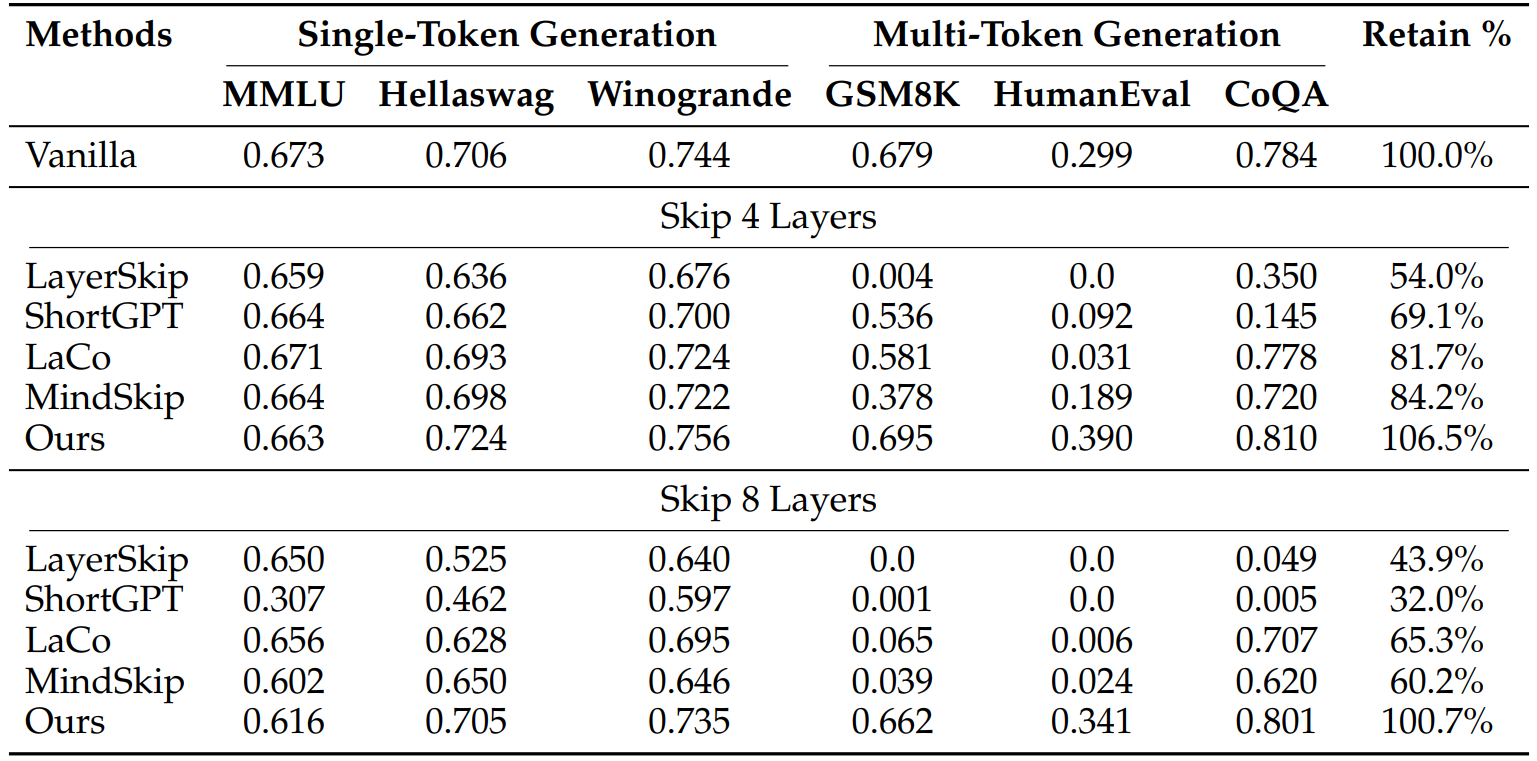
Retain % represents the percentage of average retained benchmark performance